
Nem elég tudni, mit fejlesztünk – azt is tudni kell, miből épül fel
![]() Lesku Gergely
Lesku Gergely
![]() 2026.06.04
2026.06.04
A modern alkalmazásfejlesztés egyik alapigazsága, hogy ma már ritkán írunk meg mindent nulláról. A fejlesztőcsapatok kész könyvtárakat, keretrendszereket, open source komponenseket és külső csomagokat használnak, hogy gyorsabban tudjanak szállítani, és az üzleti logikára koncentrálhassanak. Ez önmagában nem probléma, sőt: az open source ökoszisztéma az egyik legfontosabb oka annak, hogy a szoftverfejlesztés ma ilyen tempóban működik. A kérdés inkább az, hogy pontosan tudjuk-e, mit emelünk be az alkalmazásainkba – és ezek milyen kockázatokat hoznak magukkal.
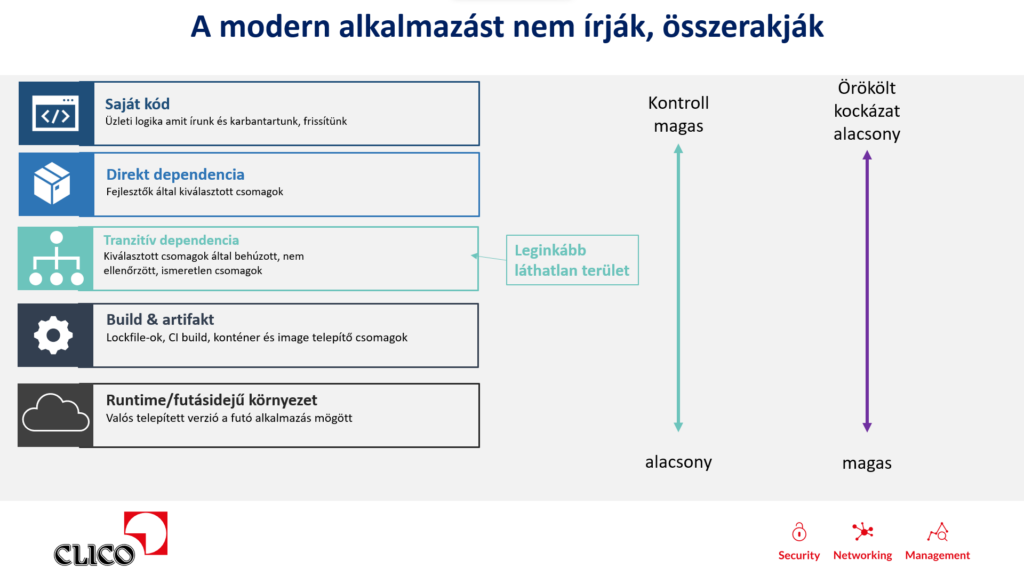
Az alkalmazásokat ma nem megírjuk, hanem összerakjuk
Egy modern alkalmazásban a saját fejlesztésű kód sokszor csak a teljes rendszer kisebb, de üzletileg kritikus részét jelenti. A hitelesítés, a HTTP-kezelés, az adatbázis-kapcsolatok, a naplózás, a fájlkezelés vagy akár a felhasználói felület egyes elemei gyakran külső komponensekre épülnek.
Ez hatékonyabbá teszi a fejlesztést, de közben új kockázati rétegeket is létrehoz. Amikor egy külső csomagot használunk, nemcsak funkcionalitást veszünk át, hanem annak teljes függőségi láncát, sérülékenységeit, licencfeltételeit és karbantartási állapotát is.
A fejlesztők által közvetlenül kiválasztott csomagokat direkt függőségeknek nevezzük. Ezek jellemzően szerepelnek a projekt manifest fájljaiban, például egy package.json, pom.xml vagy hasonló állományban. A valódi vakfolt azonban sokszor nem itt kezdődik, hanem a tranzitív függőségeknél: ezek azok a komponensek, amelyeket nem a fejlesztő választott ki, hanem a kiválasztott csomagok húznak be magukkal.
Egyetlen népszerű keretrendszer akár több tucat vagy több száz további csomagot is behozhat. Ezek ugyanúgy az alkalmazás részévé válnak, akkor is, ha a fejlesztő soha nem találkozik velük név szerint.
Miért nem elég a saját kód vizsgálata?
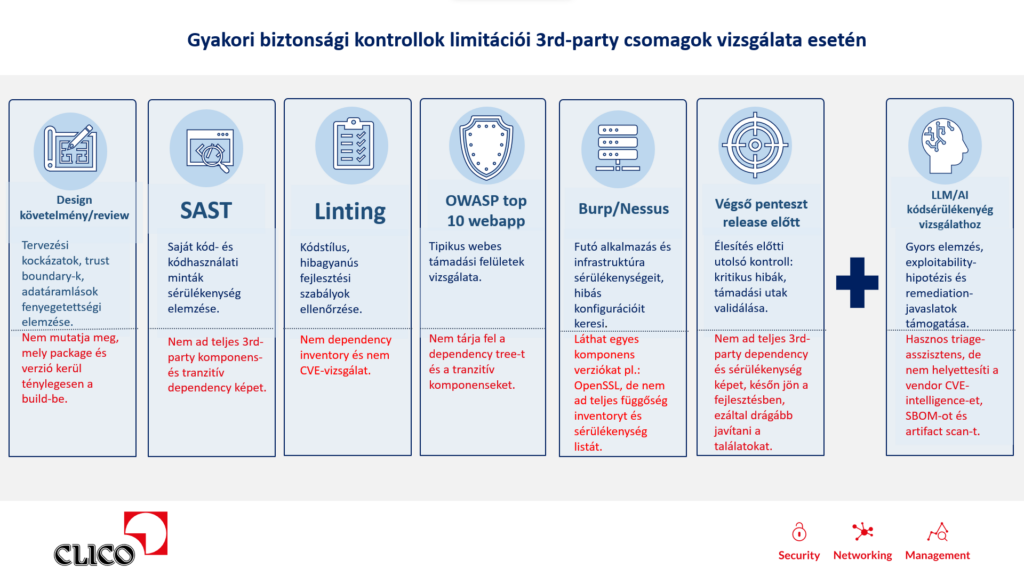
A saját kód statikus elemzése továbbra is fontos. Az üzleti logika, az egyedi funkcionalitás és a belső fejlesztésű komponensek biztonsági vizsgálata nélkülözhetetlen. De önmagában már nem ad teljes képet.
A build végén ugyanis nem a repository kerül éles környezetbe, hanem egy telepíthető artifact: például egy konténer image, egy JAR fájl, egy ZIP csomag vagy más alkalmazáscsomag. Ebben már nemcsak a saját kód van benne, hanem a direkt és tranzitív függőségek, azok licencei, metaadatai és sérülékenységei is.
Ezért nem elég azt mondani, hogy „a saját kód rendben van”. Azt is pontosan látni kell, hogy végül milyen komponensek kerültek bele az alkalmazásba, milyen verzióban, milyen licencfeltételekkel, és milyen ismert vagy potenciális kockázatokkal.
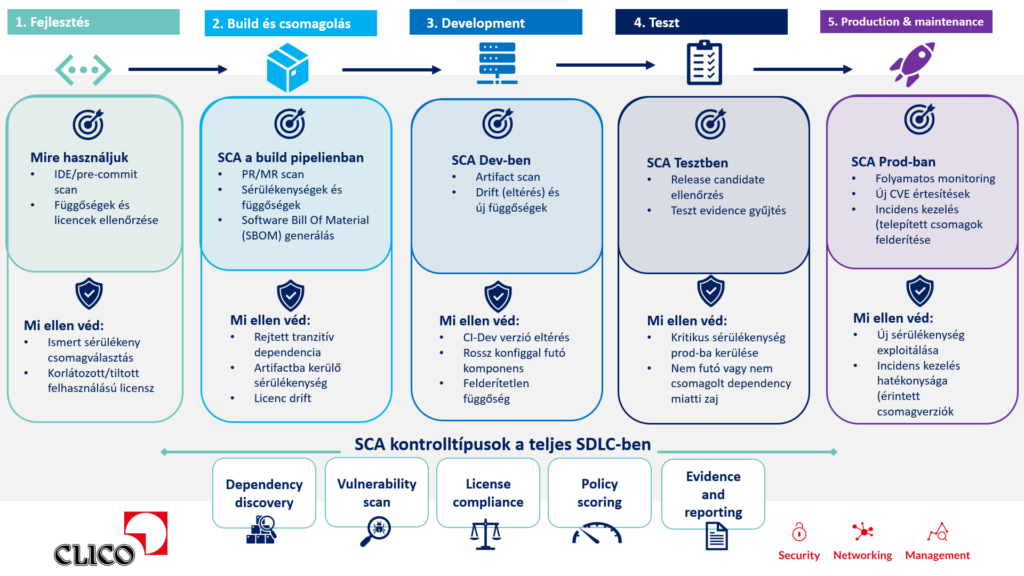
Itt lép be a képbe az SCA, vagyis a Software Composition Analysis, magyarul szoftverösszetétel-elemzés.
Mit ad az SCA?
Az SCA célja, hogy láthatóvá tegye az alkalmazás teljes összetevőlistáját. Nemcsak azt mutatja meg, hogy milyen direkt csomagokat használunk, hanem azt is, hogy ezek milyen tranzitív függőségeket hoztak magukkal.
Egy fejlettebb SCA-eszköz ennél többet is nyújt:
- feltérképezi a komponensek pontos verzióit;
- azonosítja az ismert sérülékenységeket;
- megmutatja a licenceket és a licenckötelezettségeket;
- jelzi, ha egy csomag elavult vagy nem karbantartott;
- segít megérteni, hogyan került be egy komponens az alkalmazásba;
- támogatja az SBOM, vagyis a géppel olvasható szoftver-összetevőlista előállítását.
A különbség egy egyszerű csomagkezelő-parancs és egy SCA-megoldás között jelentős. Egy package manager képes listázni a függőségeket, de jellemzően nem ad teljes biztonsági és licencelési kontextust. Nem mutatja meg, mely komponensek hordoznak kritikus sérülékenységet, melyik verzióra érdemes frissíteni, vagy hogy egy tranzitív komponens milyen úton került be az alkalmazásba.
A supply chain támadások új korszaka
A third party és open source komponensekre épülő fejlesztés a támadók számára is vonzó célpont. Sok esetben nem magát az alkalmazást támadják közvetlenül, hanem azt a környezetet, ahol a csomag települ: fejlesztői laptopot, CI-runnert, build hostot vagy konténer build környezetet.
A kockázatok több formában jelenhetnek meg:
- ismert sérülékenységek használata;
- elavult vagy nem karbantartott komponensek;
- túl tág verziótartományok;
- manifest és lock fájlok közötti eltérés;
- secretök, tokenek, API-kulcsok kiszivárgása;
- rosszindulatú csomagok;
- typosquatting vagy dependency confusion támadások.
A typosquatting esetén a támadó egy ismert csomag nevéhez nagyon hasonló nevű csomagot publikál, abban bízva, hogy a fejlesztő vagy a build folyamat tévedésből ezt húzza be. Dependency confusion esetén a támadó olyan publikus csomagot hoz létre, amelynek neve megegyezik egy belső csomagéval, és a build rendszer rossz forrásból oldja fel a függőséget.
Különösen veszélyesek azok az esetek, amikor a rosszindulatú kód már telepítéskor, például post-install script formájában lefut. Ilyenkor az sem jelent védelmet, ha az adott csomagot az alkalmazás futás közben nem is hívja meg. A build környezet maga válik támadási felületté.
Az AI-kódolás új kockázatai
Az AI-alapú coding agentek megjelenése új dimenziót ad a problémának. Ezek az eszközök képesek gyorsítani a fejlesztést, de közben csomagneveket is hallucinálhatnak: vagyis olyan jól hangzó, de valójában nem létező package-eket javasolhatnak, amelyeket a fejlesztő vagy maga az agent megpróbál telepíteni.
Ha egy támadó felismeri, hogy bizonyos hallucinált csomagnevek ismétlődnek, publikálhatja ezeket rosszindulatú kóddal egy nyilvános registry-ben. Innentől a kockázat már nem elméleti: ha az agent vagy a fejlesztő behúzza a csomagot, megtörténhet a kompromittáció.
Ez jól mutatja, hogy a szoftverellátási lánc biztonsága már nem csupán sérülékenységkezelési kérdés. Ökoszisztéma-szintű problémáról van szó, amelyben a fejlesztési folyamatok, a build környezetek, a csomagkezelés, az AI-eszközök és az üzemeltetési kontrollok egyaránt szerepet játszanak.
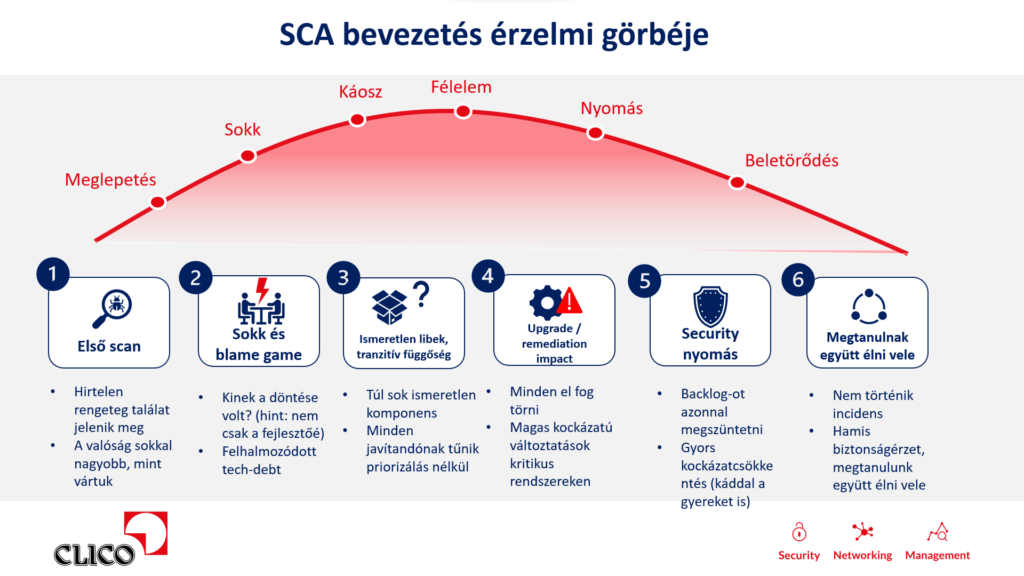
Az első SCA-futtatás sokkoló lehet
Aki először futtat SCA-vizsgálatot egy régebbi vagy nagyobb alkalmazáson, könnyen szembesülhet több száz vagy akár több ezer találattal. Ez elsőre ijesztő lehet, de nem feltétlenül azt jelenti, hogy a fejlesztőcsapat rosszul dolgozott.
A külső csomagok frissen tartása folyamatos feladat. Ha ez hosszabb időn keresztül elmarad, természetes, hogy felhalmozódnak a sérülékenységek, az elavult verziók és a licenckockázatok. Ráadásul a találatok egy része lehet false positive, vagyis olyan sérülékenység, amely az adott alkalmazási kontextusban nem kihasználható.
Ettől azonban nem szabad automatikusan figyelmen kívül hagyni a tranzitív függőségeket. Egy mélyen elhelyezkedő csomag sérülékeny függvénye is lehet valóban kihasználható, ha az alkalmazás adatfolyama végül eljut oda. Ezért fontos a triázs: el kell dönteni, mely találatok jelentenek valós kockázatot, és melyek kezelhetők alacsonyabb prioritással.
Triázs vagy frissítés?
Az SCA egyik gyakorlati kihívása, hogy sokszor nem egyértelmű, mikor érdemes mély triázst végezni, és mikor egyszerűbb frissíteni. Előfordulhat, hogy annak bizonyítása, hogy egy sérülékenység nem kihasználható, majdnem akkora munka, mint maga az upgrade.
Különösen óvatosan kell bánni a tranzitív függőségek közvetlen frissítésével. Technikailag sok környezetben lehetséges egy mélyebben lévő csomag verzióját felülírni, de ez funkcionális kockázatot hozhat be: a direkt csomagot nem feltétlenül tesztelték azzal a verzióval, amelyet mi kényszerítünk rá.
Ezért sok csapat inkább a direkt függőségeket frissíti olyan verzióra, amely már biztonságos tranzitív csomagokat húz be. Egy jó SCA-eszköz ebben is segíthet: megmutatja, melyik direkt dependency milyen verzióra frissítendő ahhoz, hogy a mélyebben lévő sérülékeny komponens eltűnjön.
Az SCA nem egyetlen pipeline-lépés
Gyakori hiba az SCA-t úgy kezelni, mint egy egyszerű CI/CD pipeline-lépést: „berakunk egy szkennert a buildbe, és kész”. Ez veszélyesen leegyszerűsíti a problémát.
Az SCA valójában több ponton is értéket adhat a szoftverfejlesztési életciklusban:
Fejlesztés közben korai visszajelzést adhat, ha valaki sérülékeny vagy tiltott licencű csomagot próbál behozni. Pull request vagy merge request szinten már kontrollpontként működhet: megmutatja, hogy egy változtatás milyen új függőségeket, sérülékenységeket vagy policy-sértéseket vezet be.
Build és release szakaszban ellenőrizhető, hogy a ténylegesen létrejött artifact mit tartalmaz. Ez különösen fontos, mert nem mindig ugyanaz kerül a buildbe, mint amit a forráskódban első ránézésre látunk. Release-nél pedig előállítható az SBOM, amely auditok, beszállítói elvárások és incidenskezelés során is kulcsfontosságú bizonyíték lehet.
Production környezetben az SCA folyamatos monitoringot is támogathat. Ami ma biztonságos komponensnek tűnik, arról holnap kiderülhet egy kritikus sérülékenység. Ilyenkor gyorsan meg kell tudni válaszolni: használjuk-e az érintett csomagot, melyik alkalmazásban, milyen verzióban, és ki a felelős a javításért.
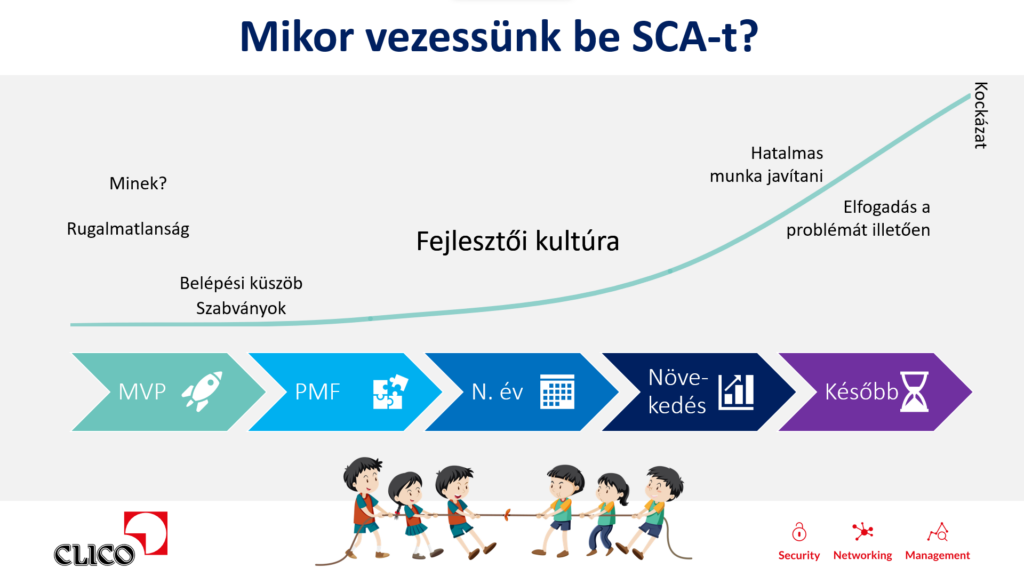
Mikor érdemes bevezetni?
Startupoknál és gyorsan változó termékeknél az SCA bevezetésének időzítése különösen fontos. A legkorábbi fázisban, amikor a termék még keresi az útját, a túl szigorú kontrollok könnyen rugalmatlanságot okozhatnak. Ugyanakkor minél tovább halogatjuk a bevezetést, annál nagyobb lesz a technológiai és biztonsági adósság.
A döntést érdemes kockázati alapon meghozni. Számít, hogy hány felhasználója van a rendszernek, milyen adatokat kezel, milyen ügyfeleket szolgál ki, és milyen piaci vagy szabályozói elvárások vonatkoznak rá. Egy B2B terméknél például egy nagyvállalati ügyfél biztonsági átvilágítása már önmagában kikényszerítheti az SCA, az SBOM és a sérülékenységkezelési folyamatok meglétét.
A bevezetést célszerű fokozatosan kezdeni. Első lépésként jöhet az alert-only mód, amikor a rendszer még nem blokkolja a buildet, csak láthatóvá teszi a problémákat. Ezután alkalmazásonként és kockázati szintenként lehet szigorítani a policy-ket.
A legfontosabb tanulság
Az open source és third party komponensek használata nem kerülendő, hanem kontrollálandó. A modern szoftverfejlesztés ezekre épül, ezért nem az a cél, hogy mindent házon belül írjunk újra. Az viszont alapkövetelmény, hogy pontosan tudjuk, milyen komponensekből áll az alkalmazásunk, ezek hogyan kerültek be, milyen sérülékenységeket és licenckötelezettségeket hordoznak, és mit kell tennünk, ha egy új kockázat megjelenik.
Az SCA ebben nem csupán egy technikai eszköz, hanem egy fejlesztési és biztonsági kontrollréteg. Láthatóvá teszi a szoftverösszetételt, támogatja a triázst, segít az SBOM előállításában, és gyorsabbá teszi az incidenskezelést.
A kérdés tehát ma már nem az, hogy használunk-e külső komponenseket. Használunk. A valódi kérdés az, hogy tudjuk-e, pontosan mit használunk – és képesek vagyunk-e időben reagálni, ha ezek közül valamelyik kockázattá válik.