
From reactive NOC to self-driving operations with HPE Networking
![]() István Laky
István Laky
![]() 2026.02.26
2026.02.26

In many NOCs, incidents still get handled only after user complaints—manual checks, ad‑hoc log hunting, and long coordination loops. As enterprise networks become more hybrid and application‑driven (Wi‑Fi + wired campus, SD‑WAN, cloud, SaaS, video), this reactive model stops scaling: symptoms show up at the user level, while root causes are spread across multiple domains.
HPE Networking (Aruba + Juniper Mist) positions an AI-native, “self-driving” operating model for the NOC: make experience measurable end‑to‑end, learn what “normal” looks like continuously, surface issues early, and guide (or selectively automate) remediation—without losing human control.
The two outcomes that matter most
NOC modernization typically aims for two practical results:
- Better user experience: track what users actually feel (Teams/Zoom quality, SaaS responsiveness, onboarding/roaming), not only device uptime and interface counters.
- Lower operational effort: faster triage, fewer escalations/war rooms, and less back‑and‑forth between network, security, and app teams.
Experience-first operations align these outcomes by translating telemetry into service-level signals that NOC teams can act on.
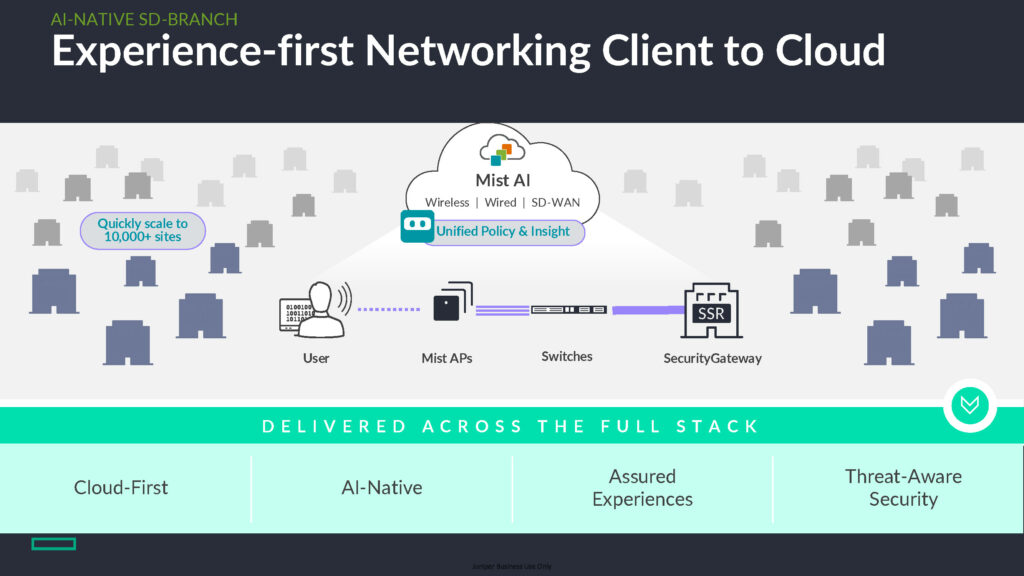
Self-driving in real terms
“Self-driving” does not mean removing engineers from the loop. In practice, it means shifting routine work from manual investigation to AI-supported decision making:
- Experience KPIs (SLE): connectivity, roaming, application experience and WAN path quality.
- Adaptive baselines: per site, client type, application and time window—so the system understands local norms.
- Explainable findings: not only alerts, but contributing drivers, correlations, and a clear “why.”
- Actionable guidance: recommended fixes, workflow integration (ITSM), and selective automation where safe.
The goal is to move from reactive troubleshooting to proactive control—and reduce resolution time from hours/days to minutes for common cases.
What to take away from the approach
The key mindset shift is that the NOC stops thinking primarily in devices and links and starts thinking in user journeys. Instead of asking “Which AP/switch is red?”, the first question becomes “Who is impacted, how, and where does experience break down?”
This matters because many incidents look similar from a device-metric perspective, yet have very different user impact. Experience-based analytics helps prioritize what matters, separate “noise” from real degradation, and keep operations aligned with business outcomes.
Common lesson from the examples: start from experience impact, then narrow down to the domain and component driving it. When you begin with “who is affected and how,” you avoid blind log hunting and reduce escalations—because the investigation is framed with context and evidence from the outset.
Why AI-native Mist beats bolt-on analytics
AI helps only if data and context are designed in from the start. With an AI-native model:
- telemetry is unified across wired, wireless and SD‑WAN;
- client/app/location context is built into analysis (not reconstructed later);
- operational workflows turn signals into decisions, not just dashboards.
Aruba + Mist combine experience measurement with an AI engine so operators work from context, not guesswork—and can act with confidence.
What Mist AI changes day to day
Juniper Mist AI typically brings three day-to-day improvements:
- Unified experience view across domains (wired/wireless/SD‑WAN) expressed as SLEs, so user complaints can be mapped to measurable indicators.
- Assistant-like investigation so teams can ask targeted questions (site, user group, application window) and jump directly to impacted clients.
- Faster root cause + next steps by starting with correlated evidence rather than manual log collection.
Common supporting tools include:
- Synthetic client for continuous, proactive experience testing (catching regressions before tickets).
- Dynamic PCAP to capture packets tied to a specific event context—useful when deeper proof is needed.
Example workflow: from question to cause
- Ask about recent experience degradation (site/users/app).
- The system lists affected users/clients quickly and highlights the strongest signals.
- Drill down to client-level evidence, correlations, and timeline.
- Get a specific cause and remediation—e.g., authentication failure tied to a PSK (not a vague “Wi‑Fi issue”).
- Validate on a timeline with related configuration changes to answer “what changed?” and reduce repeat incidents.
What you can measure after rollout
Typical NOC-side benefits that can be tracked:
- fewer tickets and shorter MTTR due to earlier detection and clearer prioritization;
- reduced OPEX via less manual triage, fewer escalations, and shorter war-room time;
- more consistent digital experience for users across sites and client types.
The longer the AI runs, the more accurate baselines and recommendations typically become—especially in distributed, multi-site environments.

A low-risk way to start
A pragmatic entry point is a focused pilot that proves operational value quickly:
- pick 1–2 sites or one critical app journey (video, SaaS, VDI);
- define expected SLE targets and success criteria (MTTR, ticket volume, top incident categories);
- validate whether insights are repeatable, explainable, and actionable for the NOC.
If “Why did experience degrade?” still triggers long troubleshooting cycles, an experience-first, AI-native NOC model is a practical route to faster, more predictable operations—without sacrificing control or governance.
Read the full article on our International subsidiary’s website by clicking on the logo:
