
AI a monitoringban: gyorsabb riasztáskezelés
![]() Al-Nuwaihi Gergő
Al-Nuwaihi Gergő
![]() 2026.03.05
2026.03.05

Az AI ma már nem „jövőkép”, hanem mindennapi adottság: évek óta velünk van gépi tanulás, mélytanulás, nyelvfeldolgozás vagy gépi látás formájában, az utóbbi években pedig a generatív AI hozott látványos ugrást tartalomautomatizálásban, hatékonyságnövelésben és gyorsabb döntéstámogatásban. A kérdés az IT-üzemeltetésben egyszerű: hogyan fordítható ez kézzelfogható előnnyé a napi hibakezelésben és a monitoring zajának csökkentésében?
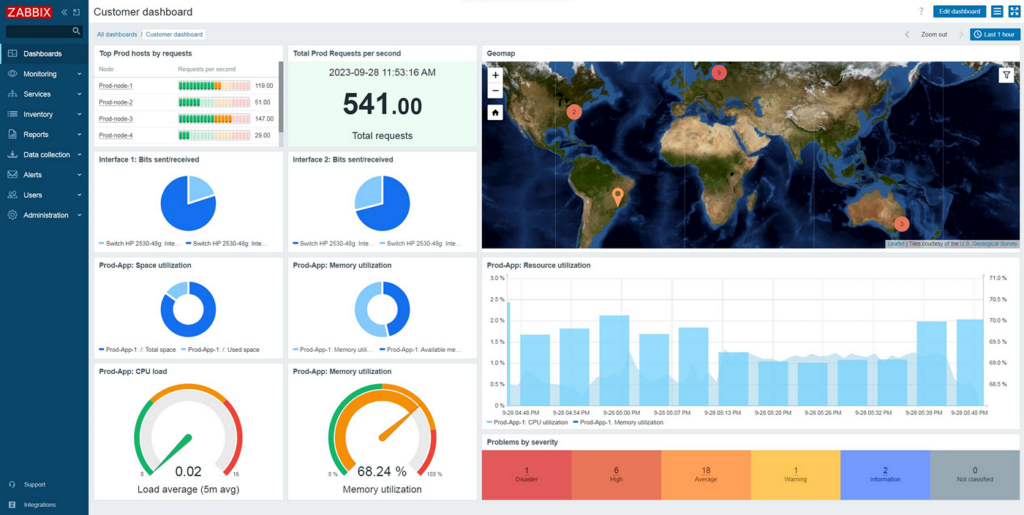
Miért kulcs a központi monitoring?
Központi monitoringra szinte minden szervezetnek szüksége van, mert így:
- egy helyen látható az összes rendszer, eszköz és szolgáltatás állapota,
- valós idejű képet ad a működésről,
- támogatja a gyors hibafelismerést és az azonnali riasztásokat,
- hosszabb távon a proaktív üzemeltetés alapja.
Emellett a monitoring nem csak „piros-zöld lámpa”: szolgáltatásmonitoringra és SLA-mérésre, trendanalízisre, jövőtervezésre, valamint integrációkra (pl. CMDB, ticketing, naplógyűjtők) is támaszkodunk.
Zabbix mint alap: stabil, skálázható, rugalmas
A Zabbix kézenfekvő választás, ha teljes körű infrastruktúra-monitoring kell:
- sablon alapú működés (gyors bevezethetőség),
- fejlett vizualizáció és dashboarding,
- skálázható architektúra (front-end/back-end felépítés, proxy funkció),
- gyártó- és platformfüggetlenség,
- agent és agentless megoldások,
- nyílt forráskód, és nagyvállalati környezetre elérhető LTS verzió.
A klasszikus monitoring-feladatok viszont ettől még megmaradnak: rendszerállapot-felügyelet, rendellenességek korai észlelése, riasztások kezelése és priorizálása, incidenskezelés támogatása, teljesítmény- és kapacitásfigyelés.
A kihívás ott kezdődik, amikor a riasztások száma és összetettsége miatt a csapat ideje egyre nagyobb része a „zaj válogatására” megy el.
AI-támogatás a riasztások kezelésének gyorsítására
Az üzemeltetésben két tipikus igény jelenik meg:
- Egyedi riasztások gyors értelmezése és a következő lépések támogatása
- Sok riasztásból a valóban kritikusak kiemelése, hogy legyen fókusz
1) Alert Assist: „mit jelent ez a riasztás, és mit csináljak most?”
Az Alert Assist egy, a Zabbix felületébe beépülő frontend modul, amely nyelvi modellel értelmezi a kiválasztott problémát, és rövid, jól olvasható támogatást ad az operátornak.
A válasz szerkezete kifejezetten üzemeltetési logikát követ:
- Lehetséges kiváltó okok: például szolgáltatásleállás, hálózati elérés/probléma, tűzfal-szűrés, hibás konfiguráció vagy túlterheltség.
- Ellenőrző lépések parancsokkal: javasolt parancsok/ellenőrzések, amelyekkel gyorsan validálható a gyanú.
- Javasolt intézkedési sorrend: mit érdemes először megnézni, mit lehet azonnal kizárni.
- Megelőzési javaslatok: hogyan csökkenthető annak esélye, hogy a hiba ismét felbukkanjon.
A cél nem az, hogy „hosszú esszét” kapjon a csapat, hanem hogy a napi operátori munkához szükséges döntési pontok gyorsabban meglegyenek – különösen hasznos ez betanulásnál, junior kollégáknál, vagy amikor a tudás szétszórtan létezik.

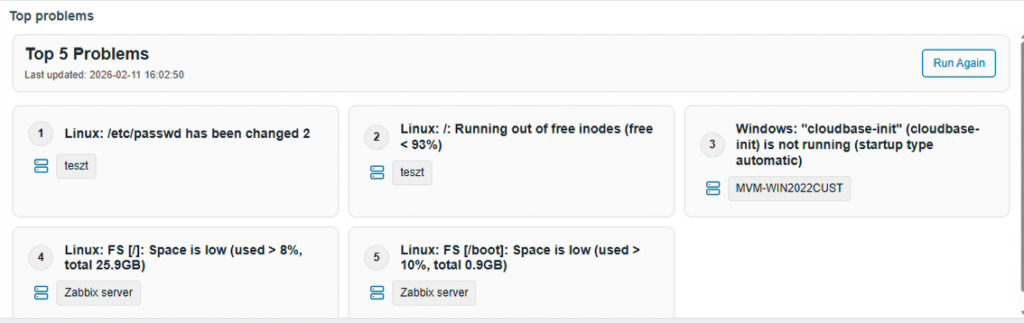
2) Priority Manager: amikor 10–20 oldalnyi riasztásból kell 5-re fókuszálni
Nagyobb, produktív környezetben tipikus, hogy a monitoring „tele van” eseménnyel. Ilyenkor a legnehezebb kérdés az, hogy mi igényel azonnali beavatkozást.
A Priority Manager egy, a felületbe illeszkedő komponens, amely az összes aktív problémát halmazként vizsgálja, majd nyelvi modell (és opcionálisan belső tudás) alapján rangsorolja a legkritikusabbakat.
A gyakorlatban ez azt jelenti, hogy:
- egy Top N lista jön létre (konfigurálható: 5/10/15 stb.),
- minden tételhez látszik a probléma típusa és az érintett környezet,
- a listában szereplő problémákra külön is kérhető javasolt intézkedés, magyarul megfogalmazva,
- lehet szűrni a válasz hosszára, illetve áttekinteni a riasztások történetét,
- és azonos jellegű problémák csoportosítva is megjelenhetnek (nem csak „szerverenként” szemlélve a helyzetet).
A hozzáadott érték itt az, hogy a csapat gyorsan rátalál a „valódi tűzre”, és a monitoringból érkező zaj kezelhetőbbé válik.
Technikai háttér: rugalmas modellválasztás, kontrollált adatkitettség
Mindkét megoldásnál fontos szempont, hogy a szervezetek eltérően állnak a felhős AI-hoz. Emiatt a kialakítás két irányt is támogat:
- On-prem futtatás: HPE GPU-s szerverrel, helyi modellekkel (pl. ollama/localai).
- Felhős LLM: igény szerint több szolgáltató API-ja felé (pl. OpenAI, Google, Amazon, Microsoft).
Gyakorlati, üzemeltetési szempontból különösen lényeges a kontroll:
- a szenzitív infrastruktúra-azonosítók (például szervernevek, IP-k) nem feltétlenül kerülnek ki a modell felé; a megközelítés anonimizálást alkalmazhat,
- a válasz minőségét pedig szándékosan kialakított system prompt segíti: rövid, operátori fókuszú, és a téves „túlköltés” (hallucináció) minimalizálására törekszik.
A rangsorolás oldala workflow-alapú automatizációként is felépíthető (nem script-ekre építve), így jól kiegészíthető belső tudással, szabályokkal és szervezeti sajátosságokkal.
Üzemeltetési előnyök: gyorsabb reakció, kisebb teher, kevesebb „zaj”
Az AI-val támogatott monitoring legfontosabb kézzelfogható előnyei:
- Gyorsabb riasztáskezelés: fókusz a kritikusokra, kevesebb idő a válogatáson.
- Üzemeltetők tehermentesítése: a rutinkörök és az első vizsgálatok egyszerűsödnek.
- L1/helpdesk szint erősítése: az AI-asszisztens támogatásával több hiba ellenőrizhető magasabb szintű eszkaláció nélkül.
- „Shadow AI” kockázat csökkentése: ha a kollégák amúgy is AI-t használnak, érdemes kontrollált, szervezeti keretek közé terelni, mit és hogyan adunk át a modellnek.
Jövőkép: agentic működés és „beszélgetés” a monitoringgal
A következő lépcső nem csak a javaslatokban van, hanem az agentic irányban: amikor a rendszer nem csupán magyaráz, hanem bizonyos, szabályozott lépésekben végre is hajt feladatokat (például ismétlődő, alacsony kockázatú teendők automatizálása, vagy a riasztások historikus értelmezése alapján a zaj csökkentése).
Ezzel párhuzamosan megjelenik az igény arra is, hogy ne csak „kattintgassuk” a felületet: egy MCP (Modell Context Protocol) szerver koncepciója azt célozza, hogy a monitoringhoz természetes nyelven lehessen kapcsolódni – ami a tanulási görbét is rövidítheti, különösen olyan eszközöknél, amelyeknél gyakori visszajelzés a komplex kezelhetőség.