
Önjáró hálózatüzemeltetés: AI ‑native NOC a HPE Networkinggel
![]() Laky István
Laky István
![]() 2026.02.26
2026.02.26

A biztonsági üzemeltetésben (SOC) már megszoktuk, hogy a riasztások özöne mellé analitika, kontextus és javasolt válaszlépések is társulnak. A hálózatüzemeltetésben (NOC) viszont sok helyen még mindig az a „klasszikus” forgatókönyv fut, hogy akkor indul a hibakeresés, amikor a felhasználó már panaszkodik – és ekkor is többnyire találgatás, kézi log‑vadászat és hosszú egyeztetések következnek.
Pedig a NOC célja ugyanaz, mint a SOC-é: a szolgáltatás minőségének folyamatos fenntartása, csak itt a fókusz a felhasználói élményen van. A kérdés az, hogyan lehet ezt skálázhatóan megoldani úgy, hogy közben a hálózat komplexitása (hibrid irodák, Wi‑Fi, SD‑WAN, felhő, videókonferencia, SaaS) folyamatosan nő.
Ebben a cikkben azt foglaljuk össze, hogyan közelíti meg a problémát a HPE Networking – és azon belül az a gondolat, hogy a hálózatüzemeltetés következő evolúciós lépése a self‑driving, AI‑native működés: a hálózat nemcsak „látható”, hanem önállóan tanul, proaktívan jelez, és a hibák nagy részét még a bejelentés előtt képes értelmezni.
Két üzleti cél, ami mindent meghatároz
A hálózatüzemeltetés modernizációját nem technológiai divatszavak indokolják, hanem két nagyon konkrét elvárás:
- A felhasználói élmény legyen a középpontban. Nem az számít, hogy „link up”, hanem hogy a Teams‑hívás, a Zoom, az üzleti alkalmazás végponttól felhőig ténylegesen jól működik‑e.
- Az üzemeltetés legyen gyorsabb és kiszámíthatóbb. Kevesebb manuális hibakeresés, kevesebb „war room”, kevesebb ping‑pong a csapatok között.
A HPE Aruba és a Juniper Mist (HPE Networking portfólióban) erre a két célra épít: experience‑first gondolkodás, és erre ráültetve egy olyan AI‑motor, amely a hálózati jelekből felhasználói élményt modellez, majd ebből döntéstámogatást és automatizációt ad.
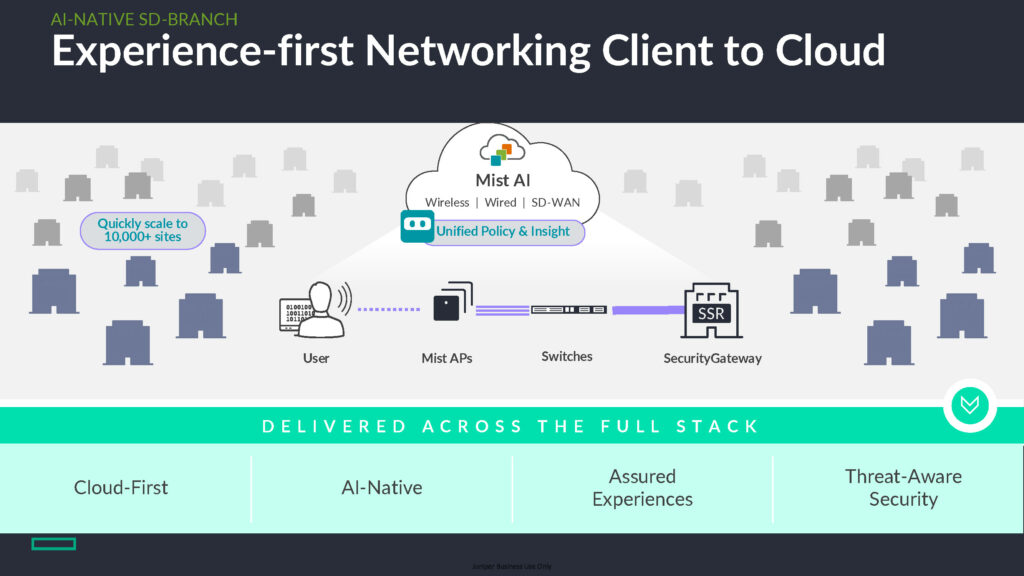
„Self‑driving network” – mit jelent ez valójában?
A „self‑driving” itt nem azt jelenti, hogy a hálózat magától „varázsol”. A valós tartalma sokkal kézzelfoghatóbb:
- Mérés a felhasználói élmény nyelvén (SLE): nem csak eszköz‑ és interfész‑metrikák, hanem Service Level Expectation jellegű mutatók (pl. alkalmazásélmény, csatlakozás, roaming, WAN‑útvonal minősége).
- Folyamatos tanulás kontextussal: a rendszer a „mi a normális” mintákat nem egyszeri beállításból veszi, hanem folyamatosan finomítja, site‑onként, kliensprofilonként, alkalmazásonként.
- Magyarázható AI‑döntések: az üzemeltető nem csak egy piros jelzést kap, hanem azt is, hogy miért gondolja a rendszer, hogy ott a probléma (okok, súlyok, összefüggések).
- Proaktív és (bizonyos esetekben) automatikus lépések: javasolt javítások, konfigurációs ajánlások, illetve integráció a folyamatkezelésbe.
A gyakorlati cél: a NOC ne csak reagáljon, hanem előre lásson, és a hibakeresés ne napokig, hanem percekig tartson.
Miért fontos az „AI‑native” megközelítés?
Hálózatüzemeltetésben az AI akkor működik, ha nem utólag próbáljuk „ráönteni” egy heterogén adathalmazra, hanem eleve úgy építjük fel a rendszert, hogy:
- a vezetékes, vezeték nélküli, SD‑WAN és biztonsági edge adatok egyetlen analitikai modellben találkoznak,
- a mérés és a kontextus (kliens, helyszín, alkalmazás, felhasználói időablak) első osztályú adat,
- a döntéstámogatás nem külön termék, hanem az üzemeltetési folyamat része.
A HPE Networking (Aruba + Juniper Mist) erre az alapról épít: a full‑stack élménymérés és az AI‑motor együtt adja azt a képességet, hogy az üzemeltetés nem „riasztásokból”, hanem összefüggésekből dolgozik.
Mit ad ehhez a Mist AI?
A Juniper Mist AI (a HPE Networking világában) a gyakorlatban három dolgot tesz hozzá a NOC mindennapjaihoz:
- Egységes élménymérés (wireless + wired + SD‑WAN + app SLE). A cél, hogy a felhasználói panaszok (pl. „szaggat a Teams”) visszavezethetők legyenek konkrét hálózati jelenségekre.
- Kérdezhető üzemeltetési nézet (VNA/asszisztens jellegű működés). Nem reportokat böngészünk, hanem célzottan rá lehet kérdezni jelenségekre és érintett kliensekre (például: volt‑e az elmúlt időszakban olyan felhasználó, aki a site‑on rossz élményt kapott).
- Gyors, kontextusos hibaanalitika és javítási javaslat. Az üzemeltető időt nyer: nem a logok összegyűjtésével kezdi, hanem egy kész elemzéssel.
Különösen érdekesek azok a kiegészítők, amelyek a klasszikus „monitoringot” élő üzemeltetési támogatássá fordítják:
- Synthetic client: folyamatos „mesterséges” felhasználói teszt a hálózaton, ami állandóan validálja az élményt.
- Dinamikus PCAP hibák esetén: ha egy jelenség bekövetkezik, a rendszer célzott csomagszintű adatot is képes társítani a hiba kontextusához.
Egy tipikus üzemeltetési helyzet – lépésről lépésre
A lényeg nem az, hogy „szép a felület”, hanem hogy milyen gyorsan jut el a NOC a kérdéstől a magyarázatig.
A felvázolt helyzet egy valós, üzemeltetésben gyakori szituációt modellezett: egy adott helyszínen/SSID-n többféle, eltérő jellegű probléma is előfordulhat, és az a kérdés, hogy ezek közül melyik érinti ténylegesen a felhasználói élményt – és mi a legvalószínűbb ok.
A folyamat röviden így áll össze:
- Természetes nyelvű kérdés felhasználói élményre: a rendszer felé az a kérés hangzott el, hogy az érintett site-on az elmúlt időszakban volt‑e olyan felhasználó, aki potenciálisan elégedetlen lehetett.
- Gyors eredménylista (másodpercek alatt): a rendszer rövid idő alatt listázta az érintett felhasználókat/klienseket – nem azt várva, hogy valaki „telefonáljon”, hanem proaktívan.
- Egy kattintás a részletekig: a kiválasztott kliensre rákattintva a NOC nézőpontból értelmezhető elemzés érkezett: mi történt, mivel függ össze, és mi a javasolt javítás.
- Konkrét ok és ajánlott lépés: a példában egy PSK‑val (pre‑shared key) kapcsolatos hitelesítési probléma adta a gyökérokot. Vagyis nem „gyenge a Wi‑Fi”, hanem konkrét, javítható ok.
- Idősáv és változások nyomon követése: a jelenség idővonalon visszanézhető, és az is látszik, hogy történt‑e konfigurációs beavatkozás (pl. ki lépett be, mi változott). Ez a NOC‑ban tipikus „ki nyúlt hozzá?” körök nagy részét kiváltja.
Az üzenet: rövid időn belül előállhat az a hibaanalitika, ami korábban több ember több óráját vitte el – és mindez a felhasználói élmény felől indítva, nem eszközmetrikákból.
Üzleti hatás: kevesebb ticket, kisebb OPEX, jobb élmény
A self‑driving megközelítés értékét a NOC oldalán nagyon gyorsan lehet mérni:
- kevesebb hibajegy és rövidebb megoldási idő, mert a problémák egy része már a bejelentés előtt azonosítható;
- alacsonyabb üzemeltetési költség (OPEX), mert csökken a manuális triázs és a többkörös egyeztetés;
- jobb digitális élmény, ami közvetlenül hat a felhasználói produktivitásra.
A HPE Aruba és Juniper Mist ügyféloldali tapasztalatai alapján a trend egyértelmű: minél tovább fut az AI‑motor, annál több mintát tanul meg, és annál nagyobb arányban képes proaktív megoldásokat adni.

Mi kell ahhoz, hogy ez működjön a valóságban?
Az AI‑támogatott NOC nem egy „bevezetünk egy eszközt és kész” projekt. Három gyakorlati fókuszponttal érdemes számolni:
- Mérés és célok tisztázása: mely alkalmazások és felhasználói folyamatok a kritikusak (Teams/Zoom, ERP, VDI, SaaS)? Ezekhez kell SLE és riportolható élménymérés.
- Adatminőség és integráció: a wired/wireless/WAN adatok egységesítése, és az ITSM/folyamatok (pl. ServiceNow) összekötése, hogy az AI‑jelzésekből valódi incidenskezelés legyen.
- Operációs működés átállítása: a csapat ne eszközök szerint, hanem élmény szerint gondolkodjon. A cél a gyors triázs és a javasolt lépések rutinná tétele.
Miért éri meg belevágni?
Ha a NOC-ban ma még a „miért romlott a felhasználói élmény?” kérdésből hosszú hibakeresés lesz, akkor itt az ideje szintet lépni. A HPE Networking (Aruba + Juniper Mist) experience‑first megközelítése SLE‑alapú élménymérést és AI‑native okfeltárást ad, hogy az üzemeltetés ne találgatásból, hanem kontextusból dolgozzon.
Üzleti oldalon ez gyorsan látszik: kevesebb ticket, alacsonyabb NOC‑OPEX, kiszámíthatóbb hibakezelés, jobb felhasználói élmény. A legjobb belépő egy rövid, célzott pilot: 1–2 kritikus site vagy alkalmazás kiválasztása, elvárt SLE‑k rögzítése, majd kézzelfogható, üzemeltethető javaslatok és megtakarítási pontok azonosítása.